


When AI Gives Advice: Validating Semantic Consistency in AI-Generated Medical Communication.

I believe that validating the semantic consistency of AI-generated medical advice requires us to carefully rethink our approach to AI medical communication verification. In healthcare, where communication errors are widely recognized as the leading cause of sentinel events, contributing to a significant proportion of adverse outcomes according to The Joint Commission, and approximately one-third of malpractice claims can be attributed to communication failures, as reported in studies published in BMJ Quality & Safety and BMJ Open. However, LLMs introduce a unique challenge: while they are capable of generating valid and contextually accurate advice, their ability to produce multiple, linguistically different explanations for the same concept can lead to confusion, especially if the foundational meaning (clinical authenticity) is lost.
In this article, I argue for the MARMAR’s validation approach through three main steps. First, I introduce the unique challenges I encountered while developing MARMAR (Medication Alert and Risk Management Application for Rx Safety), an AI-driven medication safety platform designed to prevent inappropriate polypharmacy - the use of multiple medications without clear clinical justification, leading to increased risk without a proportional benefit, which also includes prescribing cascades (WHO). Second, I explain why traditional natural language validation methods fundamentally fall short when evaluating LLM-generated medical advice, and how this limitation led to the development of the MARMAR-Semantic validation framework. Finally, I demonstrate how this framework reveals important insights about AI-generated medical communication and its potential to maintain clinical accuracy across varying levels of technical language.

The concept of semantic consistency in medical communication is more nuanced than it might first appear. Consider a well-documented drug interaction case from clinical literature: the interaction between warfarin (a blood thinner) and amiodarone (a heart rhythm medication). According to established clinical guidelines (CHEST Guidelines, 2022), this interaction typically requires warfarin dose reductions of 20-40% to maintain therapeutic INR ranges. This interaction serves as my test case because it's well-studied and has clear clinical parameters for validation.
A clinically consistent explanation must maintain its core medical meaning regardless of whether it's being conveyed to a cardiologist, a general practitioner, a pharmacist, or a patient. When MARMAR generates these explanations, it might tell a patient (In the General Explanation:
"These medications together could make your blood too thin, increasing your risk of bleeding." To a cardiologist, it might explain(In the Pharmagological explanantion): "Co-administration results in enhanced anticoagulant effects due to CYP2C9 inhibition, potentially increasing INR values by 1.5-3 fold."
While Drugbank cross-validation confirms MARMAR's clinical accuracy, this article focuses on a different challenge: can MARMAR consistently maintain clinical meaning across multiple iterations of the same case, even when expressed in different ways?"
The limitations of current verification approaches become apparent when we examine how they handle such variations. Traditional methods, often based on pattern matching or keyword identification, struggle with this complexity. They might flag these two explanations as inconsistent simply because they share few common words, missing their equivalent clinical meaning. This limitation became starkly apparent during my initial attempts to validate the consistency of MARMAR's outputs using BERT.
So In developing MARMAR's semantic validation framework, I discovered that the solution to solve this inadequacy required a combination of advanced language understanding and clinical knowledge. My initial attempts using BERT, a standard language model, yielded disappointing results with semantic similarity scores averaging around 0.36. This led to my adoption of ClinicalBERT, a model specifically trained on medical literature and clinical notes. The improvement was astounding, but maybe expected; semantic consistency scores rose to above 0.90, indicating strong preservation of medical meaning even across varying levels of technical language.
To validate the framework, I created a composite test case based on common polypharmacy patterns identified in geriatric literature (American Geriatrics Society, 2022). This test case represents a typical older adult managing multiple chronic conditions: hypertension controlled with ACE inhibitors, type 2 diabetes managed with first-line oral medications, and hyperlipidemia treated with statins. This combination was selected as it represents one of the most common medication patterns in adults over 65, according to Medicare data (CMS, 2023).".
This simplified case exemplifies the complexity of polypharmacy that many older adults face. I tested MARMAR's ability to analyze this medication profile across 100 iterations; the system needed to maintain clinical accuracy while communicating at different technical levels—from detailed pharmacological explanations for healthcare providers to accessible advice for patients like the 65-years old man.

For each field in the output, a mean ClinicalBERT similarity score was calculated to reflect how semantically consistent the responses were across iterations. This approach allowed for an assessment of how closely the responses aligned in meaning, even when phrasing varied, thereby identifying fields where semantic consistency was maintained across multiple iterations.
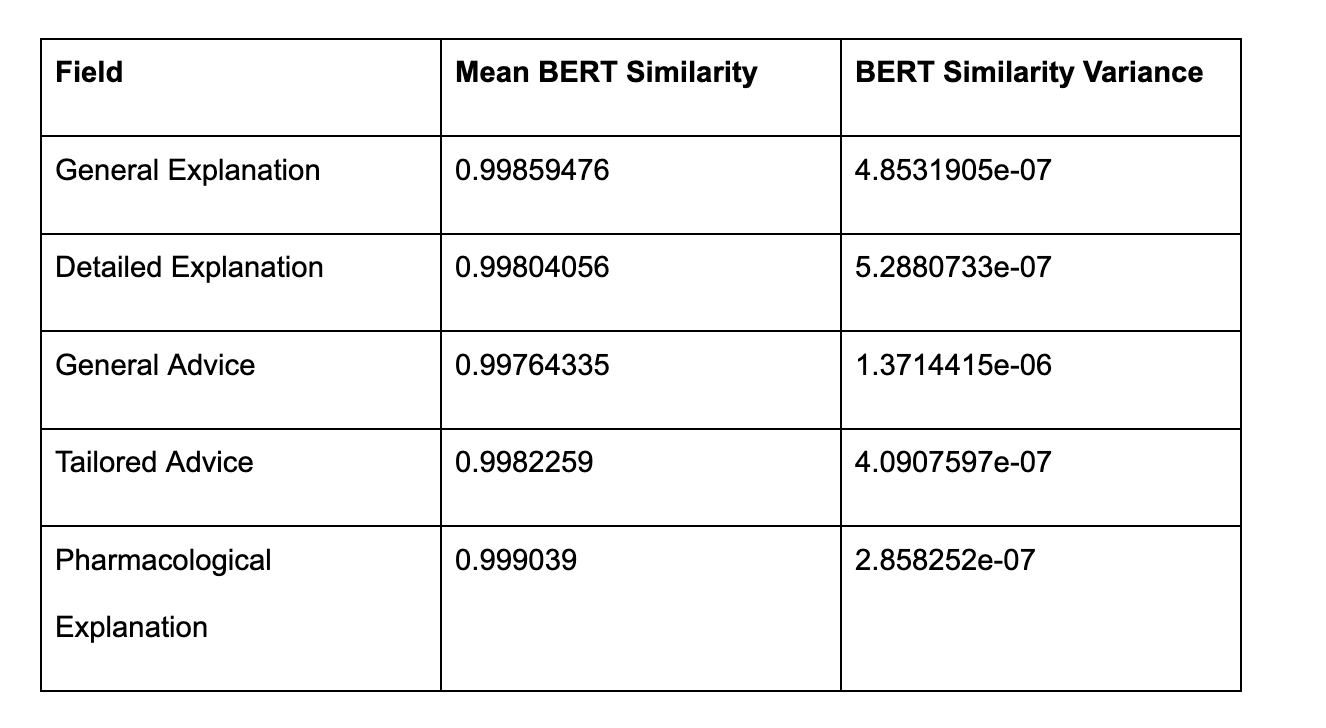
Mean ClinicalBERT Similarity: The high similarity scores across all fields, with pharmacologicalExplanation and generalExplanation nearing a mean of 0.999, indicate that MARMAR maintained a strong level of semantic consistency. These fields, which often contain technical information and standardized medical language, remained notably stable across iterations. Fields like generalAdvice and tailoredAdvice also showed high mean similarity scores, indicating that MARMAR's responses were consistent in offering guidance and advice.
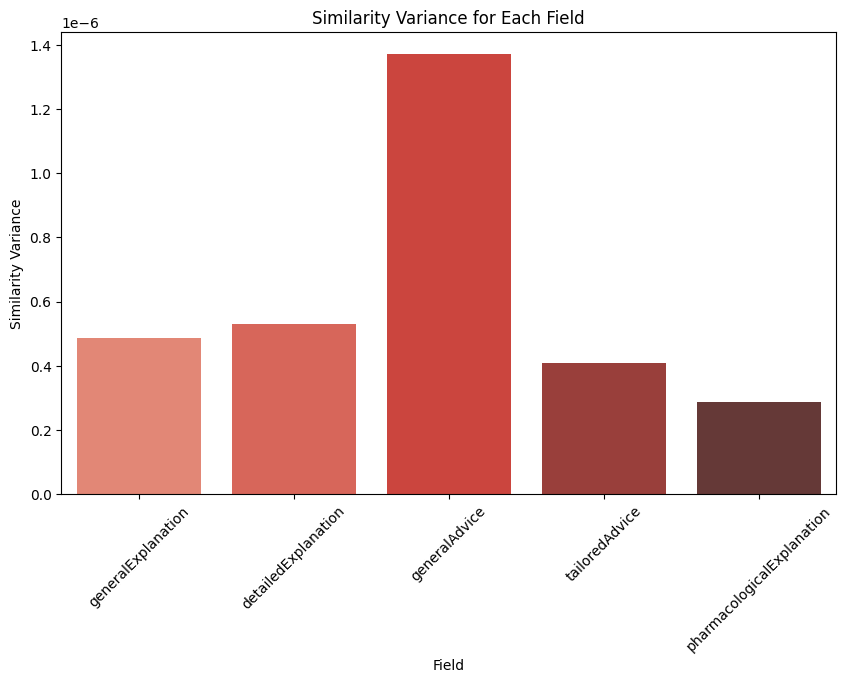
In this controlled testing environment, using standardized input cases, we observed low variance in semantic similarity scores (σ² = 1.7 × 10−7, n = 100 iterations) for technical medical content. However, these results should be interpreted within the constraints of our testing parameters and may not generalize to all clinical scenarios.
The pharmacologicalExplanation field, with the lowest variance, confirmed the stability of technical descriptions, as expected. Similarly, fields like generalAdvice and tailoredAdvice, which might typically vary due to adaptive advice, also maintained low variance, suggesting that MARMAR provided consistent, unchanging recommendations across iterations, even in fields where some flexibility could be anticipated.

MARMAR's outputs were cross-validated against DrugBank, a comprehensive pharmaceutical database, using a diverse set of 100 drugs across therapeutic categories. The detailed findings of this cross-validation analysis will be presented in another article.
The implications for AI in medicine extend beyond just medication safety. This work suggests that AI systems can successfully navigate the complex balance between technical accuracy and accessibility—a prerequisite for their integration into healthcare. For instance, when MARMAR explains a complex drug interaction, it maintains the precise medical meaning, whether it's generating technical documentation for healthcare providers or simplified explanations for patients.
Looking forward, this work suggests several crucial directions for development. We need to expand our validation frameworks to cover more aspects of medical communication, integrate real-time feedback from healthcare providers, and develop more sophisticated ways to verify clinical accuracy across different contexts. Collaboration between AI developers, healthcare providers, and medical communicators will be essential in this journey of ours.
A research prototype of MARMAR is available for academic evaluation at marmar.life. We invite healthcare professionals and researchers to explore this experimental platform and provide feedback on its validation framework. Please note: All medical decisions should be made by qualified healthcare professionals.
Validating the semantic consistency of AI-generated medical advice requires us to move beyond traditional approaches to verification. The framework I've developed demonstrates one way forward, showing how we can systematically evaluate AI-generated medical advice while ensuring it maintains consistent clinical meaning across different levels of communication. As AI continues to play a larger role in healthcare communication, such validation frameworks will be crucial in ensuring these systems can effectively bridge the gap between technical medical knowledge and accessible healthcare advice.
Limitations and Considerations:
1. Research Context: This work represents an experimental investigation into semantic validation methods for AI-generated medical communication.
2. Clinical Application: The described framework is not intended for independent clinical decision-making and has not been validated for direct clinical use.
3. Validation Scope: My findings are limited to specific test cases and controlled conditions as described.
4. Professional Oversight: Any application of these concepts in clinical settings requires appropriate medical professional oversight and validation.